
Уровень SQL-синтаксиса
Не каждый разработчик может сразу написать такой SQL-запрос, который вжух и выполнился. Иногда на это может уйти несколько итераций. Задача мониторинга — выявить такие SQL-запросы и сообщить о них кому следует. Посмотрим, где можно найти корень зла.
Статистика SQL-оптимизатора. Их много для разных БД, есть из чего выбрать. Результаты могут удивить.
Планы выполнения (execution plans). «GPS», который выдаст инструкции о том, как эффективно добраться из точки a в точку b. Иногда путь может напоминать американские горки. Планы выполнения включают ключевую информацию: индексы, связанные с объектами базы данных, и влияние/стоимость каждого шага в выполнении последовательности SQL-запросов.
Маски (wild cards). Это бич некоторых приложений. SELECT * в небольшую таблицу не вызовет значительного снижения производительности. Очевидно, что в больших БД это будет целой проблемой.
Фильтрация. Когда WHERE уже слишком поздно. Чем раньше будет сокращён общий набор данных, тем меньше нагрузка на логические и физические ресурсы.
Преобразования. Преобразование данных из одного типа в другой — дорогая операция. Если тип данных столбца varchar, а вы пытаетесь сравнить значения в этом столбце с целым числом, требуется неявное преобразование. Лучше этого избежать.
Построчная обработка. Лучше обрабатывать наборы, а не работать с с циклическим просмотром каждой строки в каждой таблице.
Индексы. Их может быть слишком много, а может быть слишком мало. В SQL Server можно непреднамеренно запретить базе данных использовать предполагаемый индекс, если поместить функцию в индексированный столбец.
Уровень экземпляра базы данных
Oracle, SQL Server, PostgreSQL, MySQL или MongoDB, каждая платформа имеет свои особенности и, соответственно, факторы производительности. Посмотрим на эти факторы.
I/O. Главная метрика ввода-вывода обычно количество логических операций чтения, выполненных конкретным оператором SQL. Стремление сократить количество операций логического чтения из базы данных — полезный скилл.
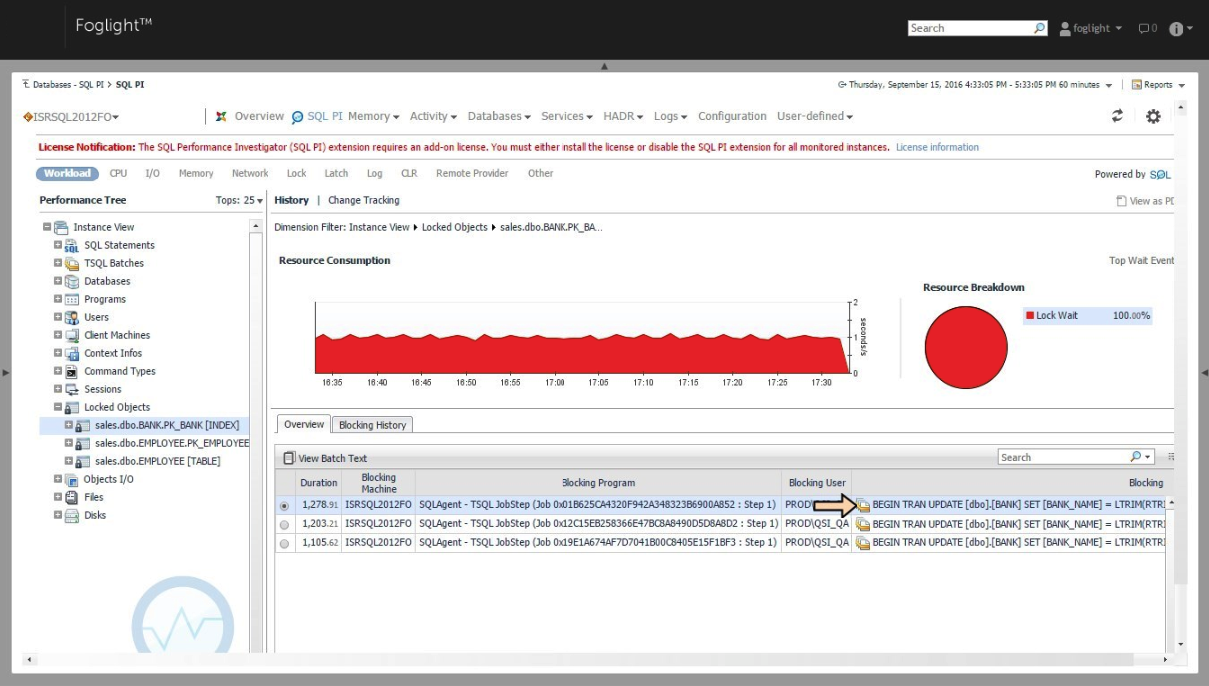
Заблокированные объекты. Блокировка лежит в основе параллелизма транзакций, то есть способности транзакции пройти тест ACID (атомарность, согласованность, изоляция, стойкость). Операторы SQL выполняются в контексте отдельных сеансов, но не все сеансы базы данных постоянно активны. Но даже и такие сеансы также могут быть заблокированы из-за блокировок в базе данных.
Анализ статистики ожидания (Wait Stat). Ожидания связаны с недостатком конкретных ресурсов, такими как процессор, память и сеть. Их недостаток может повлиять на отдельные операторы SQL, которые от них зависят. Также полезно знать, как интерпретировать различные типы ожидания, действующие в вашей базе данных, включая локировку/блокировку (LCK), проблемы ввода-вывода (PAGEIOLATCH), конкуренцию за latch (LATCH) и замедление работы сети (NETWORK).
Параметры. Каждая СУБД имеет конфигурацию, которая может значительно повлиять на её производительность. Сюда входят параметры памяти, параметры оптимизатора, параметры файлов и многое другое.
Файлы. СУБД содержат различные файлы: журналы транзакций, undo-логи и многое другое. Важно убедиться, что эти файлы правильно настроены по части их размера и других связанных параметров для обеспечения оптимальной производительности.
Уровень инфраструктуры
Здесь без сюрпризов. Это уровень операционной системы и/или физического сервера.
CPU. Каждый SQL-оператор требует треда в CPU. Какие из них потребляют больше всего тредов? Какие из них чрезмерно нагружают процессор? Есть ли тенденция к увеличению использования тредов определёнными SQL-операторами?
Память. Когда большие фрагменты ОЗУ заняты чем-то другим, другим запросам приходится ждать обработки. Углубившись в статистику использования памяти, можно определить объем памяти, который потребляет каждый SQL-оператор.
Подсистема хранения. Логические чтения выполняют ввод-вывод из оперативной памяти, но если данных нет в памяти, чтение происходит с диска. Это значительно медленнее и серьёзно влияет на производительность.
Сеть. Если вдруг появился запрос, тратящий большую часть своего времени на ASYNC_NETWORK_IO, это не обязательно означает проблему с сетью; система могла просто передавать клиенту слишком много данных. За этим параметром также нужно следить.
Уровень пользователей и сеансов
Самый обманчивый уровень из всех. Если пользователи жалуются, значит, где-то есть проблема, нужно найти ее и разобраться.
Визуализация пользовательских сессий поможет диагностировать истинную проблему и убедиться, что проблема действительно на стороне базы данных, а не рабочей станции пользователя, где одновременно воспроизводится добрый десяток роликов с Youtube.
Когда вы сталкиваетесь с жалобами на уровне пользователя, возникает невероятный соблазн перейти на уровень инфраструктуры и порешать вопросики там. Некоторые ИТ-команды больше разбираются в оборудовании, чем в диагностике, поэтому они стремятся увеличить вычислительную мощность, память, дисковое пространство и прикрутить 10-гигабитную оптику. В конце концов, если их любимый инструмент — молоток, каждая проблема выглядит как гвоздь.
В физической среде, на виртуальной машине, локально или в облаке, многоуровневый подход к мониторингу базы данных поможет быстро диагностировать истинную причину снижения производительности. С подобными задачами очень хорошо справляется инструмент для мониторинга баз данных — Quest Foglight for Databases. Мы уже несколько лет работаем с этим инструментом и можем сказать, что им вы совершенно точно обеспечите многоуровневый мониторинг, описанный в этой статье.
Подробности о нём можно узнать на специальной странице на нашем сайте.
Почитайте наши статьи о Quest Foglight for Databases на Хабре:
Как не превратиться в стрекозу, если у вас много разных баз данных
Быстрая локализация проблем производительности Microsoft SQL Server в Quest Foglight
Интерфейсы для мониторинга производительности популярных БД в Foglight for Databases
